TVMのレファレンスハードウェアVTAについて(概観、インストール編)
概要
TVMはニューラルネットアクセラレーターのコンパイル環境、デプロイ環境としてデファクトのようなものであり、pytorch,tensorflow lite,ONNXなどのフォーマットで書かれたニューラルネットをCPU,GPU,その他アクセラレーターで実行でき、ネットワークを機械学習手法を使って最適化ができる点が注目されています。
TVMが実行可能なハードウェアはニューラルアクセラレーターを作っている半導体ベンダーが独自に実装していますが、公開されてる実装情報としてVTA(Versatile Tensor Accelerator)があります。
ここではVTAの概要の紹介とインストール、実行の解説を行います。
TVM/VTAの階層構造
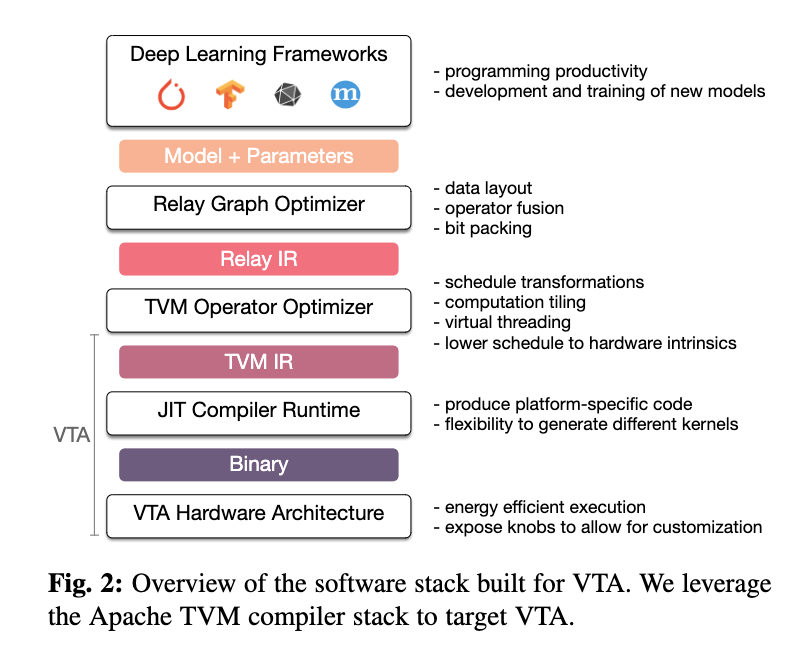
ONNX,TF,pytorchなどで書かれたモデルを中間表現Relayに変換しVTAではそれを更にTVM IRに変換、JITで実行する(A Hardware-Software Blueprint for Flexible Deep Learning Specializationより引用)。
VTA(Versatile Tensor Accelerator)

に回路構造が書かれており、
3rdparty/vta-hw-hardware/
以下にVivado HLS、ChiselとOpenCL(intelfocl)での実装ソースコードがあります。Intel(Altera)のコードは今の所実装はなさそうですがFPGAのバイナリファイルは
提供されています(VTA Installation Guide — tvm 0.11.dev0 documentation)。
実行環境
シミュレーターと実機(Pynq,DE10など)があります。
## インストール
VTA Installation Guide — tvm 0.11.dev0 documentation
TVM自体は
pip install apache-tvm
でインストールできますがVTAはソースコードを
git clone --recursive https://github.com/apache/tvm tvm
してビルドする必要があるようです。*1
VTA Installation Guide — tvm 0.11.dev0 documentation
に環境変数を設定後cmake, makeしてPython pathの追加するコマンドが書いてあります。ただしInstalling vta with docker-cpu image, but running simulation error - Apache TVM Discuss
にあるようにPYTHONPATHを
export PYTHONPATH=$TVM_HOME/python:$TVM_HOME/topi/python:$TVM_HOME/nnvm/python:${PYTHONPATH}とする必要があります。しかしこれでも
Check failed: (bf != nullptr) is false: target.build.llvm is not enabled
となりLLVMでビルドする必要があるらしくconfig.cmakeも書き換える必要があります。デフォルトではset(USE_LLVM OFF)なので
<set(USE_LLVM OFF) >set(USE_LLVM /usr/lib/llvm-10/bin/llvm-config)
FPGAの部屋 フィックスターズさんの”実践的!FPGA開発セミナー vol.10”の”Versatile Tensor Accelerator (VTA) 実機検証”をやってみる7
/tvm/src/codegen/codegen.cc:27: Check failed: bf != nullptr Target llvm is not enabled · Issue #1341 · apache/tvm · GitHub
とする*2
set(USE_CUDA ON)なども使える。
Dockerの使用
tvm/docker以下にはdockerfileが用意されていて
docker ./docker/build.sh イメージ名 ./docker/bash.sh イメージ名
イメージ名はtvm/docker/以下のファイル名で動くはずですが実際にはci_cpu,ci_gpuしか動かない状態らしいですhttps://discuss.tvm.apache.org/t/running-demo-cpu-docker-container/10494
これを実行するとTVMが利用できるはずが。
OSError: /lib/x86_64-linux-gnu/libm.so.6: version `GLIBC_2.29' not found
とのエラーが出てしまう。。。
また./docker/bash.sh ci_gpuでのエラー対応はDockerでGPUを使おうとしたらError response from daemon: linux runtime spec devices: could not select device driver “” with capabilities: [[gpu]] | cocoinit23を参照
実行
シミュレーターがインストールできたかの確認は
python3 vta/tests/python/integration/test_benchmark_topi_conv2d.py
でできます。成功するとエラーは出ず
2023-03-05 09:05:48.630 INFO load_module /tmp/tmpkell9gsr/conv2d.o VTA CONV2D TEST PASSED: Time cost = 0.0394499 sec/op, 5.86087 GOPS
とTEST PASSEDと実行時間を含んだlogが出力されます。
チュートリアル
vta/tutorials以下にpythonコードが提供されています。jupyter notebook形式は以下にあります
VTA Tutorials — tvm 0.11.dev0 documentation
行列行列積、Mxnetの画像認識モデルのデプロイ、Darknetのモデルのデプロイなどがあります。
行列行列積はte.computeでtensorflowのような計算グラフを作り、te.create_scheduleでスケジュールを作成し、vta.buildでTVMのグラフ中間表現Relayに変換し、計算を行っています。
NNモデルの読み込みはRelay.frontend.from_*という関数で行っています。
これらを詳しく見てやっていきたいです。
実機ではRPCを用いてPythonが動くホストボードが通信しています。シミュレーターと実機ボードで実行されるコードを条件分岐で切り替えています(やや読みづらい)。
Colabでも試行できるようになっていますが、mxnetのimportがうまくいかない状態でした。
発展的内容
機械学習の手法を用いて実行ハードウェア似合わせたチューニングができます。
AutoTVM 最初に提案された手法
Auto-tuning a ALU fused op on VTA — tvm 0.11.dev0 documentation
ループの最適化を遺伝的アルゴリズムで行う方法Ansor
TVMの次期自動チューニング機構(Ansor)について. AutoTVMより短い時間で高性能と噂のAnsorの技術を紹介します | by Ichiro Morinaga | nttlabs | Medium
【AI编译优化】谈谈 tvm ansor - 知乎
[2006.06762] Ansor : Generating High-Performance Tensor Programs for Deep Learning
バンディットアルゴリズムでおこなうBansor
https://cgao3.github.io/files/bansor_ictai.pdf
[2211.11172] HARL: Hierarchical Adaptive Reinforcement Learning Based Auto Scheduler for Neural Networks
リンク
ONNX infterface
tvm.relay.frontend — tvm 0.11.dev0 documentation
https://tvm.hyper.ai/docs/ 中国語版ドキュメント、チュートリアル 本家より少し充実している
XilinxのFPGAでのTVM対応 Vitis-AI/third_party/tvm at master · Xilinx/Vitis-AI · GitHub
チュートリアル https://github.com/Xilinx/Vitis-AI/blob/master/third_party/tvm/examples/external_yolov3_tutorial.ipynb
実施例jupyrerVitis-AI/third_party/tvm/examples at master · Xilinx/Vitis-AI · GitHub
TVMにて、新しいアクセラレータに対応するための仕組み、BYOC (Bring Your Own Codegen) について調べてみました - Vengineerの戯言
Apple M1への適用On Apple M1, Beating Apple’s Core ML 4 With 50% Model Performance Improvements | OctoML
ONNXをいじるだけでも相当の最適化ができるそうです。
ONNXモデルのチューニングテクニック (基礎編) | AI tech studio
ONNXモデルのチューニングテクニック (応用編1) | AI tech studio
onnx-simplifier
PyTorch, ONNX, Caffe, OpenVINO (NCHW) のモデルをTensorflow / TensorflowLite (NHWC) へお手軽に変換する - Qiita
PyTorch -> ONNX -> OpenVINO -> TensorFlow / Tensorflow Liteと変換すると最適化されやすいそうです
NHWC->NCHWはできるがNCHW->NHWCの変換は辛いらしいです。
*1:aptではなく手動でCMakeをDownload | CMakeからダウンロードしてインストールする必要があった
*2:TVMError: Check failed: bf != nullptr: Target llvm is not enabled - #2 by cchung100m - Apache TVM DiscussによるとPathでGCCのほうが先に呼ばれるようになっているのが良くないらしい。